Nommage des fichiers et gestion des versions : adopter les bons réflexes
Sommaire
Il existe des recommandations pour nommer ses fichiers de façon à pouvoir les classer de manière efficace. Dans un ensemble de fichiers ou de documents, des noms « normalisés », cohérents et comportant des éléments discriminants (comme la date de production) permettent également d’appréhender plus facilement le contenu du fichier ou du document avant même de l’ouvrir. Pour cela, il peut par exemple être utile dans le schéma de nommage des fichiers d’inclure des métadonnées importantes (par ex : [Date]_[Run]_[SampleType].)
Ces règles peuvent même être formalisées dans une convention de nommage, à l’image de ce qu’a entrepris la NASA ou l’organisme américain ARM sur l’étude des changements climatiques.
Cette convention, qui clarifie un certain nombre d’informations descriptives du contenu (date, lieu, version, auteur, etc.), peut être indiquée dans un fichier “readme” en marge des jeux de données.
Bien nommer ses fichiers
Plusieurs universités ou organismes recensent les bonnes pratiques pour le nommage des fichiers (voir ressources ci-dessous)
Il peut être recommandé :
- D’éviter les noms trop longs (ne pas dépasser 25 caractères)
- D’écarter les caractères non alphanumériques dans les noms de fichiers. Pour séparer les éléments de nommage, préférer également les underscores aux espaces qui peuvent être interprétés différemment selon les systèmes d’exploitation.
- De normaliser les dates : le format recommandé par la norme internationale ISO 8601 est: YYYY-MM-DD (year-month-day ou année-mois-jour).
Pour aider à définir les règles de nommage, il peut être pertinent de prendre en compte, l’acronyme du projet, les différents types de données (par exemple, observations de terrain sous forme de tableau, simulations, protocoles, etc.), les formats de fichiers (.csv, .jpeg, .fid etc.), les caractéristiques uniques des fichiers de données (par exemple, date de création, nom du projet, conditions expérimentales), les abréviations « standards » pour certaines de ces caractéristiques, les initiales du chercheurs et la version du fichier. Par exemple :
- Nom ou acronyme du projet ou de l’expérience
- Localisation/coordonnées spatiales
- Nom/initiales du chercheur
- Date ou fourchette de dates de l’expérience
- Type de données
- Conditions
- Numéro de version du dossier
Ex : MMDDYYYYTHH:MM_ProjIDXX_expXX_v01.csv
Date_identifiant du projet_identifiant expérience_version
Au début d’un projet de recherche, il est également important de prévoir une organisation de l’arborescence des dossiers et des fichiers qui permettent de retrouver facilement et rapidement les éléments dont on a besoin. C’est d’autant plus fondamental quand plusieurs personnes, voire une équipe collaborent aux mêmes recherche ou quand elles se succèdent.
Il est généralement conseillé de limiter le nombre de niveaux à l’intérieur des dossiers à trois ou quatre maximum et de ne pas avoir plus de dix éléments dans chaque liste.
Dans l’organisation des dossiers, il peut être pertinent de distinguer régulièrement les travaux en cours de ceux qui sont terminés : il est utile tout au long du projet d’évaluer les documents contenus dans les différents dossiers de façon à vérifier que certains dossiers ou certains fichiers ne sont pas conservés inutilement ou ne doivent pas être déplacés. De même que les conventions de nommage de fichiers, cette organisation doit idéalement être documentée et partagée (par ex, via un fichier readme).
Nikola Vukovic, chercheur en neurosciences à l’UC San Francisco, propose un type d’organisation par projet, distinguant la gestion de projets avec les éléments administratifs et financiers, l’aspect éthique, les expériences avec les différents états des données et enfin les publications. Ce type d’organisation peut s’adapter à de nombreuses disciplines.
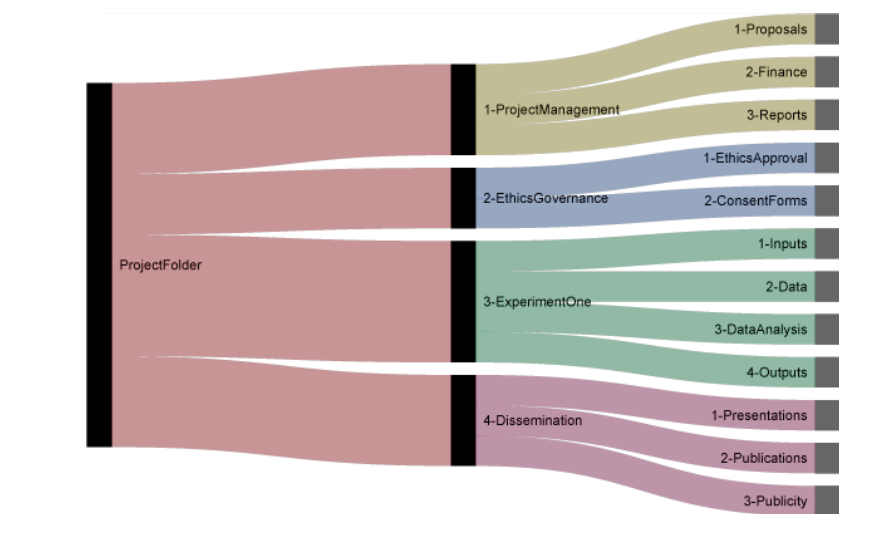
Enfin, afin de faciliter la gestion de projet et la collaboration en matière de recherche, des chercheurs allemands proposent un modèle d’arborescence de dossiers disponible ici. Cette proposition s’inscrit dans la continuité d’un travail d’enquête mené auprès de 3 laboratoires de neurosciences en Allemagne et dont les résultats sont disponibles ici.
- Plusieurs ressources généralistes peuvent vous aider :
o INRAE récapitule les préconisations principales.
o Le MIT fournit une page d’aide pour concevoir un nommage pertinent des fichiers.
o L’Université d’Edimbourg et le Digital Curation Center précisent les 13 règles à suivre pour un nommage des fichiers efficace, notamment pour la conservation des mails ou des pièces jointes.
o L’Université de Stanford présente plusieurs études de cas : données collectées par une doctorante et des bonnes pratiques.
o L’Université de Cambridge propose une vidéo de 8 mn sur le nommage des fichiers “File naming” particulièrement adapté aux développeurs et un exemple très complet de convention élaboré par l’Université de Queensland
Gérer ses versions
Certaines branches de la chimie, comme la chimie computationnelle, ou de la physique nécessitent la création et l’édition de programmes informatiques afin de réaliser des calculs spécifiques. Lorsque l’on gère des fichiers et des scripts quotidiennement, la gestion des versions ne peut être négligée.
En effet, on peut être amené à devoir revenir sur une version antérieure d’un script si les analyses obtenues ne s’avèrent pas correctes, ou si l’on souhaite modifier la direction que prendrait le projet.
Des logiciels dédiés au versionnage vous permettent de tenir un historique et de garder une trace de toutes les modifications réalisées sur un fichier. C’est le cas de Git, logiciel open source largement utilisé dans le monde de la recherche. Git vous permet de travailler sur des fichiers locaux ou de manière collaborative en réseau. Cependant, son fonctionnement peut dérouter. En effet, pour apprécier toutes les fonctionnalités de l’outil, il faut passer par le terminal et des lignes de commande.
Un certain nombre d’interfaces graphiques utilisateur permettent néanmoins de s’émanciper en partie des lignes de commandes. Vous retrouverez la liste de ces interfaces ici (la plupart sont gratuites). Il est important de noter que ces interfaces couvrent uniquement certaines parties des fonctionnalités de Git ! Le choix de l’interface graphique doit se faire en fonction de vos besoins. Cependant, certaines solutions se démarquent par leur popularité comme l’interface gratuite Git for Windows. GitHub propose également une interface pour bureau Windows, téléchargeable ici.
Pour plus d’information sur Git, vous pouvez vous tourner vers la documentation officielle disponible ici. Par ailleurs, ce guide en français vous permettra peut-être, grâce à ses illustrations, de mieux comprendre la façon dont fonctionne le logiciel.
Dans son billet publié le 26 juin intitulé “The 6 Git Commands Data Scientist Should Know”, le blog Towards data science récapitule les 6 verbes vous permettant de gérer un projet, de créer un répertoire sur Github
Pour finir, il faut se poser la question du stockage des répertoires. Le serveur de votre laboratoire ou de votre institution est un premier point d’entrée. Mais si vous souhaitez partager votre projet de manière plus ouverte, vous pouvez utiliser un hébergeur comme GitHub ou GitLab. Ces deux outils basés sur Git vous permettront de contribuer efficacement à un espace de travail de collaborer facilement. GitLab est open source. GitHub est quant à lui plus utilisé aujourd’hui mais il est propriétaire. On peut y trouver des projets en chimie computationnelle comme OpenChem, développé par l’Université de Caroline du Nord.
Pour aller plus loin, l’Australian National Data Service (ANDS), dans sa rubrique “working with data”, propose un point complet sur la gestion des versions des données avec des exemples, des scénarios et des outils.